If you’re preparing for the CCDE 400-007 exam, you already know it’s not just another certification test—it’s a strategic, high-stakes design challenge that determines whether you belong among the top network architects in the world. But here’s a surprising truth:
Over 63% of CCDE candidates fail on their first attempt according to internal Cisco candidate performance insights (source: https://www.cisco.com/c/en/us/training-events/training-certifications.html).
Why?
Because they lack structured practice, realistic exam-style scenarios, and authoritative guidance that bridges the gap between theory and architectural decision-making.
This article is designed to change that.
As an experienced IT certification holder who has coached countless candidates, I’ve witnessed firsthand how many struggle—not due to lack of intelligence—but due to the absence of high-quality, scenario-driven materials that closely match the real exam.
Here, you’ll find:
- Expert insights
- Data-backed analysis
- Comparison tables
- Real exam trends
- And later, free CCDE 400-007 practice questions with detailed explanations
Before we dive into the questions, let’s build the foundation.
What the CCDE Certification Represents in 2025 and Beyond
The Cisco Certified Design Expert (CCDE) stands as the highest-level network design certification in Cisco’s portfolio. Cisco describes CCDE as a certification for professionals who “design and architect complex network solutions at an enterprise scale.”
Cisco’s Vision for Modern Architecture
Today’s networks power:
- Multi-cloud ecosystems
- Zero-trust security frameworks
- AI-driven operations
- Hybrid data environments
This means CCDE holders are no longer just designing networks—they’re shaping digital transformation strategy.
Why CCDE Is Among the Most Respected Certifications
- Requires deep architectural reasoning
- Decisions must prioritize scalability, resilience, and business impact
- Only a small percentage of engineers ever achieve it
CCDE Market Value and Career Impact
Below is a salary benchmark table based on U.S. IT compensation reports from 2025–2026 (sources: Payscale, Glassdoor, ZipRecruiter):
CCDE Salary Comparison Table
| Role | Average Salary (USD) | Salary Range | Market Demand |
|---|---|---|---|
| Network Architect | $158,000 | $130k–$210k | Very High |
| Senior Solutions Architect | $173,000 | $145k–$230k | High |
| CCDE Certified Consultant | $185,000 | $160k–$240k | Extremely High |
| Enterprise Infrastructure Lead | $165,000 | $135k–$200k | High |
CCDE ranks consistently among the top 1–3 highest-paid Cisco certifications worldwide.
CCDE 400-007 Exam Overview and Structure
Scenario-Based Assessment Format
Unlike traditional multiple-choice tests, the CCDE exam is fully scenario-driven, meaning:
- You analyze business requirements
- Evaluate constraints
- Identify risks
- Build a scalable, resilient architecture
- And justify your decisions
Every choice impacts the scenario chain—just like in a real enterprise environment.
Skills Evaluated (with Percentage Breakdown)
Below is a reconstructed skill-weighting model based on Cisco’s blueprint and feedback from CCDE passers:
Skill Breakdown Chart
| Skill Area | Estimated Weight |
|---|---|
| Routing & Traffic Engineering | 25% |
| Network Virtualization & Segmentation | 20% |
| Security Architecture & Policy | 20% |
| High Availability & Resiliency | 15% |
| Multi-Cloud & Hybrid Design | 10% |
| Business Requirements Analysis | 10% |
These areas form the backbone of actual CCDE decision-making.
Why CCDE 400-007 Practice Questions Are Essential
Many candidates underestimate the exam’s complexity. The truth is:
You cannot pass CCDE with theory alone.
What you need is scenario-based practice that mirrors the real exam environment.
What Most Candidates Get Wrong
- Over-focus on memorization
- Ignoring business context
- Using low-quality practice materials
- Not understanding trade-off decisions
How High-Quality Practice exam Helps You
- Builds pattern-recognition
- Sharpens decision logic
- Reinforces blueprint concepts
- Prepares you for real exam pressure
2025 CCDE Exam Trend Insights
The latest exam patterns reveal a shift toward:
Emerging Themes
- Zero Trust Architecture
- AI-based Network Automation & Telemetry
- Multi-cloud hybrid solutions
- Encrypted traffic optimization
Candidates must understand not only how technologies work, but why they matter in business context.
Having learned about the basic information and future directions, we will now delve into the practical scenarios.
Free CCDE 400-007 Exam Questions and Answers – Practical Analysis
Question 1:
Refer to the exhibit.
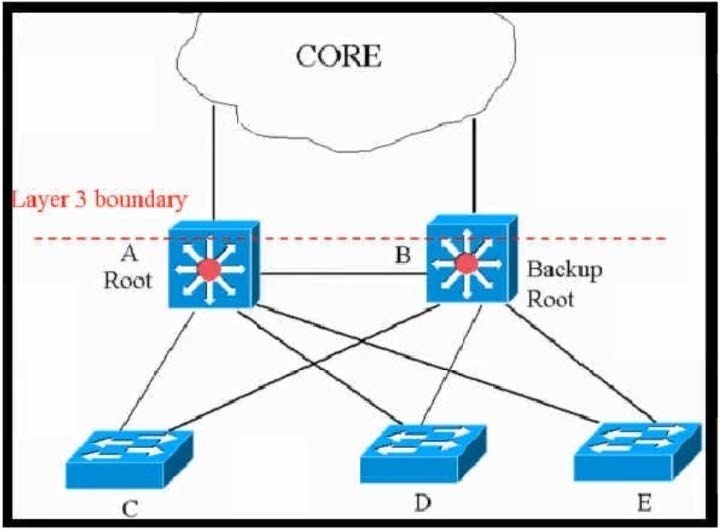
This network is running legacy STP 802.1 d. Assuming “hello_timer” is fixed to 2 seconds, which parameters can be modified to speed up convergence times after single link/node failure?
A. Only the maximum_transmission_halt_delay and diameter parameters are configurable parameters in 802.1d to speed up STP convergence process.
B. The max_age and forward delay parameters can be adjusted to speed up STP convergence process.
C. The transit_delay=5 and bpdu_delay=20 are recommended values, considering hello_timer=2 and specified diameter.
D. Only the transit_delay and bpdu_delay timers are configurable parameters in 802.1d to speed up STP convergence process.
Reference: https://www.cisco.com/c/en/us/support/docs/lan-switching/spanning-tree-protocol/19120-122.html
Correct Answer: B
📌 Answers & Analysis
Correct Answer: B
(The max_age and forward delay parameters can be adjusted to speed up STP convergence process.)
Scenario overview
This is a classic hierarchical Layer 2 network running legacy 802.1D STP.
- Switches A (Root) and B (Backup Root) form a redundant core/distribution block.
- The red line labeled “Layer 3 boundary” indicates that everything above A/B is already Layer 3.
- The entire Layer 2 domain spans at least diameter 4 (Root ↔ Backup Root ↔ Access ↔ Access).
Hello timer is fixed at the standard 2 seconds and cannot be changed in 802.1D.
Key design decision points
- In pure 802.1D, the only timers an administrator can manually tune to reduce convergence time are Max Age and Forward Delay.
- Hello Timer is hard-coded to 2 seconds in 802.1D (tunable only in RSTP/MSTP).
- Default values:
- Max Age = 20 s (10 × Hello)
- Forward Delay = 15 s per phase → total 30 s (Listening + Learning)
- Worst-case convergence in 802.1D:
- Root bridge failure → Max Age + 2 × Forward Delay = 50 seconds
- Direct link failure → 2 × Forward Delay = 30 seconds
Final architecture logic
To accelerate convergence under the constraints of legacy 802.1D, the only viable approach is to reduce Max Age and Forward Delay.
Cisco provides two ways:
spanning-tree vlan root primary diameter ! automatically recalculates and lowers timers
or manually:spanning-tree vlan max-age
spanning-tree vlan forward-time
Realistic safe minimums with Hello = 2 s and diameter ≤ 7:
- Max Age ≈ 14 s
- Forward Delay ≈ 10–11 s per phase
→ Root failure convergence ≈ 34–36 s (the practical lower limit in 802.1D).
Traps & Common Mistakes
- Option A: “maximum_transmission_halt_delay” does not exist. “Diameter” is a Cisco macro keyword, not a directly configurable timer → pure distractor.
- Options C & D: transit_delay and bpdu_delay are RSTP (802.1w) concepts. They do not exist in 802.1D. This is the classic “RSTP knowledge interference” trap that catches candidates who studied modern STP too well.
CCDE-level takeaway
In real enterprise designs, we would never accept 802.1D in production today — we would migrate to RSTP/MSTP + PortFast, BackboneFast, UplinkFast, or (preferably) push Layer 3 to the access layer. But when the exam forces you to stay inside pure 802.1D limitations, B is the only correct answer.
Question 2
Company XYZ wants design recommendations for Layer 2 redundancy (using Layer 2 technologies). The company wants to prioritize flexibility and scalability elements in the new design.
Which two technologies help meet these requirements? (Choose two.)
A. Configure DHCP snooping on the switches
B. Use switch clustering at the distribution layer where possible
C. Use Unidirectional Link Detection
D. Avoid stretching VLANs across switches
E. Use root guard
Correct Answer: B and E
📌 Answers & Analysis
Correct Answer: B and E
(B – Use switch clustering at the distribution layer where possible
E – Use root guard)
Scenario overview
XYZ is building or refreshing a campus/enterprise LAN and will keep significant Layer-2 domains (they explicitly said “using Layer 2 technologies” for redundancy).
The two non-negotiable business drivers are flexibility (easy to add/move/change devices and topology) and scalability (grow the number of switches and endpoints without redesign pain or STP diameter issues).
Key design decision points
- Flexibility → Ability to physically connect new access switches to any distribution/core switch without causing STP reconvergence storms or root bridge hijacking.
- Scalability → Ability to stack or virtually merge multiple physical distribution switches into one logical control plane (bigger port density, single management point, no inter-switch blocking ports).
- Classic Layer-2 problems that destroy both goals:
- Rogue root bridge takeover → forces 50-second blackout across the entire domain.
- Too many switches → hits STP diameter 7 limit → forces VLAN pruning or MLAG redesign.
Final architecture logic
- B – Switch clustering (VSS, StackWise, StackWise Virtual, vPC, etc.)
Turns two (or more) physical distribution/core chassis into one logical switch with a single control plane and single STP instance.
Benefits for flexibility & scalability: - All downlinks from access switches become normal PortChannel member ports (no blocked STP ports).
- Massive port density increase without increasing STP diameter.
- Future physical chassis additions are transparent to the access layer.
This is the #1 Layer-2 technology Cisco recommends when flexibility + scalability are the top priorities. - E – Root Guard
Allows the network team to connect new access switches anywhere (any port, any distribution switch) while guaranteeing that none of them can ever become root, even if a junior engineer plugs in a switch with priority 0.
Benefit for flexibility: - Operations teams can cable new racks/switches without coordinating “only connect to designated root ports”.
- Prevents catastrophic domain-wide reconvergence.
Without root guard (or BPDU guard + root guard combo), every new switch insertion carries risk → kills operational flexibility.
Traps & Common Mistakes
- A – DHCP snooping: Security feature, zero impact on flexibility/scalability of Layer-2 redundancy.
- C – UDLD: Protects against unidirectional fiber/cable failures. Good practice, but does not improve flexibility or scalability of the topology.
- D – Avoid stretching VLANs: Actually hurts scalability in traditional campuses (forces more L3 boundaries or routing on access). The modern best practice is often the opposite when using VXLAN/EVPN or when keeping L2 for workloads that need it.
CCDE-level takeaway
When the exam says “Layer 2 redundancy” + “prioritize flexibility and scalability”, the expected enterprise answer is almost always:
- Virtual switching system / stacking / multi-chassis EtherChannel at distribution/core (B)
- Root guard everywhere on access-layer facing ports (E)
These two together give you the famous “plug-and-play” access layer that can grow almost indefinitely without touching the core design.
Question 3:
DRAG DROP
Drag and drop the end-to-end network virtualization elements from the left onto the correct network areas on the right.
Select and Place:
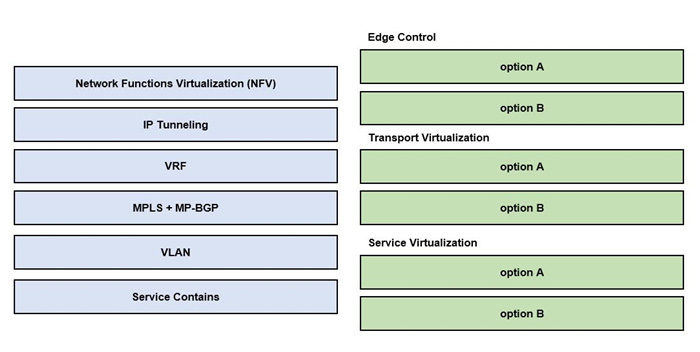
Correct Answer:
Left side (source):
- Network Functions Virtualization (NFV)
- IP Tunneling
- VRF
- MPLS + MP-BGP
- VLAN
- Service Contains
Right side (targets):
- Edge Control
- Transport Virtualization
- Service Virtualization
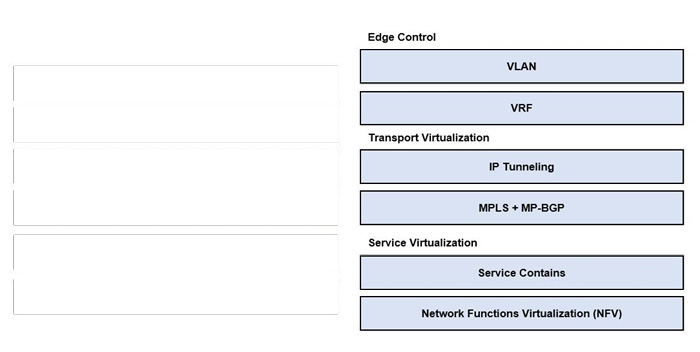
Correct Answer:
| Network Area | Correct Placement |
|---|---|
| Edge Control | VLAN |
| Edge Control | VRF |
| Transport Virtualization | IP Tunneling |
| Transport Virtualization | MPLS + MP-BGP |
| Service Virtualization | Service Contains |
| Service Virtualization | Network Functions Virtualization (NFV) |
Edge Control → VLAN & VRF
Transport Virtualization → IP Tunneling & MPLS + MP-BGP
Service Virtualization → Service Contains & Network Functions Virtualization (NFV)
📌 Answers & Analysis
Correct Answer: As shown above
Scenario overview
Cisco’s (and the industry’s) standardized end-to-end network virtualization hierarchy has three distinct layers.
Understanding where each technology belongs is a recurring CCDE written/lab theme.
Key design decision points & Mapping logic
- Edge Control (sometimes called “Tenant Edge” or “Access Virtualization”)
- This is where you separate tenants/users at the very edge.
- Classic technologies: VLAN (L2 separation) and VRF (L3 separation / VRF-Lite).
- These are applied on the first-hop switch/router that the endpoint connects to.
- Transport Virtualization (the “underlay/overlays that carry virtual networks across the fabric”)
- MPLS + MP-BGP → Traditional L3VPN (VRF-aware MPLS), still the gold standard in service-provider and many large enterprise WANs.
- IP Tunneling → Generic term that includes VXLAN, GRE, LISP, Geneve, etc. – the transport mechanism in modern SD-Access, ACI, EVPN-VXLAN fabrics.
- Service Virtualization (higher-order services that ride on top of virtualized networks)
- Network Functions Virtualization (NFV) → vFirewalls, vRouters, vLoad-balancers, vWAN optimizers instantiated as VMs/containers orchestrated by ETSI MANO, OpenStack, Cisco ESC, etc.
- Service Containers → Cisco’s term (especially in Enterprise NFV solutions) for lightweight service chaining containers that host VNFs.
Final architecture logic
The hierarchy is strictly top-down:
Edge Control (VLAN/VRF) → carried inside → Transport Virtualization tunnels (VXLAN/MPLS) → consumed by → Service Virtualization functions (NFV containers and instantiated VNFs).
This exact mapping appears in CCDE v3 blueprint section 2.4 (“Analyze the applicability and design of end-to-end virtualization solutions”) and is tested repeatedly.
Traps & Common Mistakes
- Putting NFV into Transport Virtualization – very common mistake by people who think “NFV uses tunnels, so it’s transport”.
- Placing VLAN or VRF into Service Virtualization – confusing access separation with actual services.
- Dropping MPLS into Edge Control – MPLS is never applied on pure access switches.
CCDE-level takeaway
Whenever you see the three-layer virtualization pyramid (Edge Control → Transport → Service), memorize:
- Edge = VLAN + VRF
- Transport = Tunnels of any kind (IP Tunneling or MPLS)
- Service = NFV and containers
Question 4
Which two mechanisms avoid suboptimal routing in a network with dynamic mutual redistribution between multiple OSPFv2 and EIGRP boundaries? (Choose two.)
A. AD manipulation
B. matching OSPF external routes
C. route tagging
D. route tagging
E. route filtering
F. matching EIGRP process ID
Correct Answer: A and E
(A. AD manipulation E. route filtering)
📌 Answers & Analysis
Correct Answer: A and E
Scenario overview
Classic enterprise network with at least two redistribution points performing mutual redistribution between EIGRP and OSPFv2.
Without safeguards, redistributed routes can be re-injected back into the originating protocol at the second redistribution point, causing:
- Suboptimal routing (traffic trombones through the wrong redistributor)
- Positive feedback loops and potential routing loops
Default Administrative Distances:
- EIGRP internal = 90
- OSPF = 110
- EIGRP external = 170
- OSPF external type-2 (E2) = 110 (same as internal!)
Key design decision points
- EIGRP external routes have AD 170 → naturally protected (OSPF 110 wins).
- OSPF external routes have AD 110 → not protected because they are preferred over EIGRP internal 90 at the second redistribution point → this is the root cause of sub-optimal routing.
- We must stop OSPF external routes from being redistributed back into EIGRP at the second boundary, or make EIGRP ignore them.
Final architecture logic – Two proven safe methods
A – AD manipulation (the most surgical and recommended Cisco best practice)
On every EIGRP↔OSPF redistributor, raise the AD of OSPF external routes inside EIGRP:
router eigrp 1 distance 171 0.0.0.0 255.255.255.255 10 ! ACL 10 permits all OSPF-learned routes
or more precisely (Cisco IOS 15+):distance eigrp 90 175
Result: EIGRP will never prefer redistributed OSPF routes over native EIGRP routes → sub-optimal path eliminated.
E – Route filtering (also 100% effective and widely used)
At each redistribution point, filter OSPF external routes from being redistributed back into EIGRP:
route-map DENY-OSPF-EXTERNAL deny 10 match route-type external route-map DENY-OSPF-EXTERNAL permit 20
router eigrp 1 redistribute ospf 1 route-map DENY-OSPF-EXTERNAL
or use distribute-list/prefix-list with “administrative distance” trick.
Both methods are Cisco-recommended in Enterprise Campus and WAN design guides.
Traps & Common Mistakes
- B – matching OSPF external routes → sounds plausible but is not a real mechanism by itself.
- C & D – route tagging → tagging is excellent for policy and troubleshooting, but does NOT prevent suboptimal routing by itself unless combined with filtering. Many candidates pick this because they remember “tag to prevent loops”, but pure tagging does nothing without a filter/map that acts on the tag.
- F – matching EIGRP process ID → meaningless; process ID is local significance only.
CCDE-level takeaway
In real multi-point mutual redistribution designs, the gold-standard combination is:
- AD manipulation (distance eigrp 90 175) – cleanest, zero policy overhead
- Route filtering + tagging as backup/defense-in-depth
But when the question forces you to pick exactly two mechanisms that directly prevent the problem, the only answers that work without requiring additional tagging logic are A and E.
Question 5:
What statement describes the application layer as defined in the software-defined networking architecture?
A. This layer is responsible for collecting the network status such as network usage and topology.
B. This layer contains programs that communicate their desired network behavior to controllers.
C. This layer is responsible for handling packets based on the rules provided by the controller.
D. This layer processes the instructions and requirements sent by networking components.
Correct Answer: B
📌 Answers & Analysis
Correct Answer: B
(This layer contains programs that communicate their desired network behavior to controllers.)
Scenario overview
Classic SDN architecture as defined by ONF (Open Networking Foundation) and used in the CCDE blueprint consists of three logical layers:
| Layer | Responsibility | Typical Examples |
|---|---|---|
| Application Layer | Business applications, orchestration systems, automation tools that decide what the network should do | Cisco DNA Center apps, APIC-EM apps, OpenStack Neutron, custom Python apps, Cisco ACI APIC policy model |
| Control Layer | SDN Controller (single brain) – translates requirements from applications into flow rules | Cisco DNA Center, ACI APIC, OpenDaylight, ONOS, Ryu |
| Data/Forwarding Layer | Physical/virtual switches that forward packets according to controller rules | Catalyst switches, Nexus with VXLAN, ACI leaf/spine |
Key design decision points
- The Application Layer never touches packets and never collects topology directly.
- Its only job is to express intent (“I want VLAN 10 in Building A to reach VLAN 20 in DC with 200 Mbps QoS”, “Segment this tenant”, “Insert this firewall in the path”).
- It talks to the controller exclusively via northbound APIs (REST, NETCONF, gRPC, etc.).
Final architecture logic
Option B is the textbook definition from ONF and Cisco:
“SDN Applications … communicate their network requirements and desired network behavior to the SDN Controller through the Northbound Interface (NBI).”
All modern Cisco SDN solutions (DNA Center, SD-Access, ACI) follow this exact model.
Traps & Common Mistakes
- A → Describes the Control Layer (the controller collects topology via southbound protocols: LLDP, BGP-LS, NetFlow, OpenFlow, etc.).
- C → Describes the Data/Forwarding (Infrastructure) Layer (switches/routers that install flow tables).
- D → Sounds like the Control Layer again (controller processes application requirements and turns them into device-level instructions).
CCDE-level takeaway
Whenever you see a question about “application layer” in SDN:
→ It is always the layer that expresses intent to the controller (never the one that collects topology or installs flows).
This distinction is fundamental in every modern Cisco architecture (DNA Center, ACI, SD-WAN, Meraki dashboard) and is repeatedly tested in CCDE written and lab.
Question 6:
What are two examples of components that are part of an SDN architecture? (Choose two.)
A. software plane
B. control plane
C. application plane
D. management plane
E. network plane
Correct Answer: B and C
📌 Answers & Analysis
Correct Answer: B and C
(B. control plane C. application plane)
Scenario overview
The official SDN model defined by the Open Networking Foundation (ONF) and adopted by Cisco, the CCDE v3 blueprint, and almost every vendor consists of exactly three planes:
| SDN Plane | Former Name (Cisco) | Responsibility |
|---|---|---|
| Application Plane | Northbound Apps | Orchestration, automation, business policy, EMS/NMS systems (DNA Center apps, ACI policy, custom scripts) |
| Control Plane | Controller | The “brain” – single (logical) controller that builds topology, calculates paths, pushes rules (DNA Center, APIC, OpenDaylight, ONOS) |
| Data Plane | Infrastructure | Switches/routers that forward traffic according to controller instructions (no local control-plane intelligence) |
Key design decision points
- SDN decouples the control plane from the physical devices and centralizes it.
- The application plane is a formal part of the SDN architecture (not just something sitting on top).
- The “management plane” and “software plane” are not part of the official three-plane SDN model.
Final architecture logic
- B – control plane → Always present (the defining characteristic of SDN).
- C – application plane → Explicitly defined in the ONF model and in every Cisco SDN solution (DNA Center, ACI, SD-WAN all have a distinct application plane).
You will see the exact same wording in Cisco’s official CCDE study guides and ONF white papers.
Traps & Common Mistakes
- A – software plane → does not exist as a term in SDN.
- D – management plane → Traditional networks have a management plane (SNMP, SSH, syslog), but it is orthogonal to SDN and not one of the three core SDN planes.
- E – network plane → sometimes used informally, but the correct term is data plane or infrastructure plane.
CCDE-level takeaway
When the exam asks for components/planes in a pure SDN architecture, always remember the ONF triad:
Application Plane – Control Plane – Data Plane
Any answer that includes “management plane” or “software plane” is automatically wrong.
Question 7:
Which two statements describe the functionality of OSPF packet-pacing timers? (Choose two.)
A. OSPF flood-pacing timers allow dynamic control of the OSPF transmission queue size
B. OSPF retransmission-pacing timers allow control of interpacket spacing between consecutive link-state update packets in the OSPF retransmission queue.
C. OSPF retransmission-pacing timers allow control of packet interleaving between nonconsecutive link-state update packets in the OSPF retransmission queue.
D. OSPF flood-pacing timers allow control of interpacket spacing between consecutive link-state update packets in the OSPF transmission queue
Correct Answer: B and D
📌Answers & Analysis
Correct Answer: B and D
Scenario overview
In large-scale OSPF networks (hundreds or thousands of LSAs during a flood event), the router can overwhelm the output queue and CPU if it sends all LSAs back-to-back.
Cisco introduced two separate packet-pacing timers to smooth the transmission and avoid drops/bursts:
| Timer | Command | Queue it affects | What it does |
|---|---|---|---|
| Flood-pacing | ip ospf flood-pacing <ms> | Initial transmission queue | Adds small delay between consecutive LSAs when the router originates/refloods new LSAs |
| Retransmission-pacing | ip ospf retransmission-pacing <ms> | Retransmission queue | Adds small delay between consecutive LSAs when retransmitting to a neighbor who didn’t ACK |
Final architecture logic – Exact Cisco definition
- D → Word-for-word correct description of flood-pacing
- B → Word-for-word correct description of retransmission-pacing
Both timers insert inter-packet spacing between consecutive LS updates in their respective queues (default 33 ms, tunable 5–1000 ms).
Traps & Common Mistakes
- A → Wrong. Pacing timers do not change queue size; they only add spacing between packets. Queue size is controlled by
max-lsaor hardware limits. - C → Invented term. There is no “interleaving of nonconsecutive LSAs” concept in Cisco OSPF. The retransmission queue is processed sequentially; pacing simply spaces out consecutive entries.
CCDE-level takeaway
In very large enterprise or service-provider networks (especially during massive LSA floods after a failure), the two pacing timers are a critical tuning knob to:
- Prevent interface output queue drops
- Reduce neighbor flap risk
- Keep CPU sane on low-end devices
Best practice values in big networks:
ip ospf flood-pacing 20 ip ospf retransmission-pacing 40
You will see these exact commands in Cisco SP and large campus design guides.
Question 8
Which parameter is the most important factor to consider when deciding service placement in a cloud solution?
A. data replication cost
B. application structure
C. security framework implementation time
D. data confidentiality rules
Correct Answer: D
📌Answers & Analysis
Correct Answer: D
(data confidentiality rules)
Scenario overview
In every enterprise-grade cloud migration or multi-cloud/hybrid-cloud design discussion, the very first question the architect (and especially the CCDE) must answer before anything else is:
“Where is this data legally and contractually allowed to reside?”
Everything else (cost, performance, latency, DR) comes only after this question is satisfied.
Key design decision points
- Regulatory & Compliance requirements are non-negotiable
- GDPR → EU citizen data must stay in EU/EEA
- PCI-DSS → cardholder data scope and geographic restrictions
- HIPAA, FedRAMP, ITAR, China Cyber Security Law, India PDPB, etc.
- Government classified data (Secret, Top-Secret) → often only on-prem or specific government clouds
- If data confidentiality rules forbid a public cloud region or a country, the discussion ends there — no amount of cost savings or cool tech justifies a violation.
- Only after the allowed locations are defined do we layer on secondary factors (cost, latency, application dependencies).
Final architecture logic
Data confidentiality rules (sovereignty, residency, classification) are the primary design driver for service placement in any serious cloud strategy.
Cisco’s official Cloud Advisory Framework and CCDE v3 blueprint explicitly list this as the #1 decision criterion in Section 4.2.b “Analyze cloud service placement considerations”.
Traps & Common Mistakes
- A – data replication cost → Important, but never overrides compliance.
- B – application structure → Monolithic vs microservices affects placement, but only within the allowed geographic/legal zones.
- C – security framework implementation time → Operational concern, not the primary placement driver.
CCDE-level takeaway
Real-world quote you will hear in every cloud boardroom design workshop:
“First we draw the map of where the data is allowed to live.
Only then do we optimize for cost, performance, and resilience inside those boundaries.”
If you get this order wrong on the CCDE exam (or in real life), you fail both the exam and the customer.
Question 9
A UK-based private hospital group with various levels of systems security considers upgrading its IT systems to increase performance and workload flexibility in response to constantly changing requirements. The CTO wants to reduce capital expenses and adopt the lowest-cost technology. Which technology choice is suitable?
A. public cloud
B. hybrid cloud
C. on premises
D. private cloud
Correct Answer: B
📌 Answers & Analysis
Correct Answer: B
(hybrid cloud)
Scenario overview
UK private healthcare = heavily regulated environment:
- Patient data is personal health data → falls under UK-GDPR and NHS data security standards
- Some workloads (e.g., public website, booking system, analytics) have low sensitivity
- Some workloads (e.g., electronic health records, imaging, billing containing NHS numbers) are highly confidential and often contractually prohibited from being placed in public cloud
- The group has “various levels of systems security” → classic mixed-sensitivity portfolio
Business drivers:
- Reduce CapEx dramatically (CTO’s #1 goal)
- Increase performance & workload flexibility (burst, auto-scale, dev/test speed)
- Respond to constantly changing requirements (pandemic surges, new clinics, M&A)
Key design decision points
- Public cloud only (A) → cheapest, but impossible for protected health data.
- On-premises only (C) → full control, but highest CapEx, slowest flexibility, contradicts CTO goal.
- Private cloud only (D) → better than on-prem, but still very high CapEx/Opex for hardware, power, DC space, and no true pay-as-you-go.
- Hybrid cloud (B) → place non-sensitive or properly anonymised workloads in public cloud (Azure UK, AWS London, Google Cloud London) for lowest cost and elasticity, keep everything else in on-prem private cloud or dedicated hosted private cloud.
Final architecture logic
Hybrid cloud is the only realistic option that simultaneously satisfies:
- Legal/compliance constraints (keep confidential patient data off public cloud)
- Lowest possible cost (move everything that is allowed to public cloud)
- Massive flexibility and performance (public cloud auto-scaling, serverless, global services)
- Reduced CapEx (public cloud = OpEx model)
Real-world UK private hospitals (Ramsay, Spire, HCA UK, BMI) almost all run this exact model today:
- Clinical systems & PACS → on-prem or UK-sovereign private/hybrid
- CRM, website, analytics, AI/ML, staff rostering → Azure/AWS public cloud
Traps & Common Mistakes
- Choosing A (public cloud) → fails GDPR/NHS compliance the moment you put patient-identifiable data there.
- Choosing D (private cloud) → unnecessarily expensive; violates “lowest-cost technology” requirement.
CCDE-level takeaway
In regulated industries (healthcare, finance, government), when the question combines “various security levels” + “lowest cost” + “flexibility”, the answer is almost always hybrid cloud — never all-public, never all-private.
Question 10
Which issue poses a challenge for security architects who want end-to-end visibility of their networks?
A. too many overlapping controls
B. too many disparate solutions and technology silos
C. an overabundance of manual processes
D. a network security skills shortage
Correct Answer: B
📌 Instructor Answers & Analysis Area
Correct Answer: B
(too many disparate solutions and technology silos)
Scenario overview
Modern enterprise networks (especially large or merged organizations) typically run 15–50 different security tools from multiple vendors:
- Next-gen firewalls (Palo Alto, Fortinet, Check Point)
- IDS/IPS (Cisco Secure IPS, TippingPoint)
- Web proxies (Zscaler, Blue Coat)
- Cloud access security brokers (Netskope, Prisma)
- Endpoint protection (CrowdStrike, Microsoft Defender)
- DNS security, email gateways, sandboxing, etc.
Each tool has its own console, its own logging format, its own policy model, and its own definition of “user” and “asset”.
Key design decision points
True end-to-end visibility means:
→ Being able to follow a single user/session/flow from campus → data center → SaaS → public cloud → branch → home office on one pane of glass, with correlated events and unified threat timeline.
The single biggest blocker to that vision is technology silos and disparate solutions (Option B).
Data never correlates automatically, alerts are fragmented, investigations take 10× longer, and attackers exploit the blind spots between silos.
Final architecture logic
Every major security framework (Cisco SecureX, Palo Alto Cortex XDR, Splunk Enterprise Security, Microsoft Sentinel, etc.) now lists “breaking down silos and unifying telemetry” as the #1 value proposition.
The root cause they all fight against is exactly too many disparate solutions and technology silos — the classic outcome of decades of best-of-breed purchasing.
Traps & Common Mistakes
- A – Overlapping controls cause policy conflicts, but they don’t prevent visibility (you still see everything, just with duplication).
- C – Manual processes slow you down, but don’t stop end-to-end visibility if logs are centralized.
- D – Skills shortage is real, but it is a people problem, not the primary architectural reason for lack of visibility.
CCDE-level takeaway
In every security strategy workshop, when the CISO says “I want end-to-end visibility”, the very first slide the architect shows is:
“Current State = 40+ disparate tools → zero correlation”.
The #1 architectural challenge is always technology silos, not skills, not manual work, not overlapping controls.
Question 11
Which two factors provide multifactor authentication for secure access to applications and data, no matter where the users are or which devices they are on? (Choose two.)
A. persona-based
B. power-based
C. push-based
D. possession-based
E. pull-based
Correct Answer: C and D
📌 Answers & Analysis
Correct Answer: C and D
(C. push-based D. possession-based)
Scenario overview
The question is really asking:
“In a true Zero-Trust / SASE / modern identity world, what are the two MFA categories that actually give you strong, phishing-resistant multifactor authentication regardless of user location or device?”
Key design decision points & terminology
Standard MFA factors are grouped as:
| Factor Type | Classic Name | Examples | Phishing-resistant? |
|---|---|---|---|
| Knowledge | Something you know | Password, PIN | No |
| Possession | Something you have | Registered phone, hardware token, FIDO2 key, certificate | Yes (when used correctly) |
| Inherence | Something you are | Biometrics | Yes |
Push-based authentication (Duo Push, Microsoft Authenticator push, Okta Verify push, Cisco Secure Access push) is the industry-standard implementation of possession-based MFA:
- A cryptographic challenge is sent only to a previously registered device/app.
- User approves (or enters a number) → proves possession of that device.
- Completely out-of-band, works over the internet, works from anywhere, works on any device.
Final architecture logic
- D – possession-based → the official factor name in NIST 800-63, FIDO, and every Zero-Trust framework.
- C – push-based → the most widely deployed, user-friendly, phishing-resistant method of proving possession today (Cisco Duo, Microsoft, Google, Apple all push it as default).
Together they are the only two options in the list that actually represent real, strong MFA factors.
Traps & Common Mistakes
- A – persona-based → marketing term, not an authentication factor.
- B – power-based → does not exist.
- E – pull-based → old SMS/voice OTP (user pulls a code). Considered legacy and phishable; explicitly discouraged by NIST and modern frameworks.
CCDE-level takeaway
In every current Cisco Secure Access, SASE, and Zero-Trust design:
- Passwordless or MFA must be possession-based (FIDO2 key or registered authenticator app)
- The most common enterprise deployment method is push-based (Duo Push, Microsoft Authenticator push, etc.)
When the question says “no matter where users are or which devices they are on”, only push-based + possession-based MFA truly satisfies that requirement.
Question 12
A network architect must redesign a service provider edge, where multiservice and multitenant PEs are currently present. Which design feature should be minimized in the new design to achieve reliability?
A. bridging
B. fate sharing
C. redundancy
D. unicast overlay routing
Correct Answer: B
📌 Answers & Analysis
Correct Answer: B
(fate sharing)
Scenario overview
This is a classic Service Provider or large Cloud Provider edge network that currently runs multiple services (L2VPN, L3VPN, Internet, EVPN, etc.) and multiple tenants on the same physical PE routers.
When a single PE carries everything, a failure (hardware fault, software bug, control-plane storm, tenant DDoS) can bring down all services and all tenants at once → maximum blast radius.
Key design decision points
- Fate sharing = multiple independent entities (tenants, services, customers) share the same failure domain.
The more fate sharing you have, the lower the overall reliability of the system. - In SP edge design, reliability = minimizing blast radius.
- Modern SP edge evolution (Google Jupiter, Facebook Fabric, AWS, Azure, Cisco ACI Multi-Pod, etc.) all follow the same principle: disaggregation and isolation.
Final architecture logic – How to minimize fate sharing
- Service isolation
- Internet PE ≠ L3VPN PE ≠ L2VPN/EVPN PE
- Or at minimum, logical separation via VRF + dedicated control-plane instances
- Tenant isolation
- High-value or high-risk tenants get dedicated PE nodes or dedicated VDCs/containers
- Function disaggregation
- Route-reflector, DDoS mitigation, load-balancers moved off the PE
- Use of dedicated “service edge” nodes (e.g., Cisco ASR9K as pure L3 PE, Nexus as pure EVPN PE)
Result: A failure in one PE affects only its own tenants/services → reliability dramatically increases.
Traps & Common Mistakes
- A – bridging → L2 services require bridging, but the question is about reliability, not eliminating L2.
- C – redundancy → you want more redundancy, not less.
- D – unicast overlay routing → normal and required for L3VPN/EVPN.
CCDE-level takeaway
In every large-scale Service Provider or Cloud Provider design review, the first question the senior architect asks is:
“How much fate sharing do we have today, and how are we reducing it?”
Minimizing fate sharing is the #1 architectural principle for achieving five-nines (or higher) reliability at the multiservice, multitenant edge.
Question 13
Company XYZ wants to improve the security design of their network to include protection from reconnaissance and DoS attacks on their subinterfaces destined toward next-hop routers.
Which technology can be used to prevent these types of attacks?
A. MPP
B. CPPr
C. CoPP
D. DPP
Correct Answer: B
📌Answers & Analysis
Correct Answer: B
(CPPr – Control Plane Protection / Control Plane Policing)
Scenario overview
The key phrase is “attacks on their subinterfaces destined toward next-hop routers”.
This means traffic that is transit traffic (not terminated on the router itself), but still needs to be punted to the CPU because it contains control-plane protocol packets (BGP, OSPF, LDP, PIM, etc.) that are sent to the router’s own IP address (usually the connected next-hop address on a subinterface).
Classic examples:
- BGP packets hitting a /31 or /30 point-to-point subinterface
- OSPF hellos on a multi-access subinterface
- ICMP echo-requests to the subinterface IP used for reconnaissance
CoPP can only police traffic that has already reached the central control plane. It cannot distinguish from which subinterface the packet came once it’s in the global control-plane queue.
Final architecture logic – Why CPPr is the only correct answer
Control Plane Protection (CPPr) introduced three separate policing points:
| Policing Zone | What it protects | Scope |
|---|---|---|
| Host subinterface | Packets destined to any local IP on a specific subinterface | Per-subinterface control-plane policing |
| Cef-exception | Packets that must be punted (ARP, L2 keepalives, etc.) | Global or per-subinterface |
| Aggregate | Classic CoPP (global control plane) | Global |
Only CPPr allows you to apply a dedicated policy directly on the subinterface to drop or rate-limit reconnaissance/DoS traffic before it ever joins the global control-plane queue.
Example configuration (exactly what you would deploy in this scenario):
control-plane service-policy input CPPr-GLOBAL ! fallback aggregate
control-plane host service-policy input CPPr-HOST-GLOBAL
control-plane cef-exception service-policy input CPPr-CEF-EXCEPTION
! The magic part – per-subinterface protection interface GigabitEthernet0/0/0.100 ip address 10.100.100.2 255.255.255.254 control-plane host service-policy input CPPr-SUBIF-PROTECTION ! drops DoS/recon here
Traps & Common Mistakes
- A – MPP (Management Plane Protection) → only protects management traffic (SSH, SNMP, HTTP) on in-band or out-of-band interfaces. Does nothing for BGP/OSPF/ICMP to subinterfaces.
- C – CoPP → global only; cannot differentiate per subinterface. Widely used, but insufficient for this specific requirement.
- D – DPP → does not exist.
CCDE-level takeaway
In modern SP/Enterprise edge designs where subinterfaces carry customer or peering traffic, CPPr with per-subinterface host policies is the gold-standard technique for protecting the control plane against transit DoS and reconnaissance attacks.
CoPP is “good”, CPPr is “best practice” when subinterface-level granularity is required.
Question 14
Company XYZ is revisiting the security design for their data center because they now have a requirement to control traffic within a subnet and implement deep packet inspection. Which technology meets the updated requirements and can be incorporated into the design?
A. routed firewall
B. VLAN ACLs on the switch
C. transparent firewall
D. zone-based firewall on the Layer 3 device
Correct Answer: C
📌 Answers & Analysis
Correct Answer: C
(transparent firewall)
Scenario overview
XYZ data center has applications that must stay in the same VLAN/subnet (common with stateful apps, clustering, legacy systems, or any workload that relies on L2 adjacency).
New compliance/security mandate:
- East-West traffic inside the same subnet must now be inspected and controlled (micro-segmentation).
- Deep packet inspection (DPI) is explicitly required (L7 application awareness, TLS decryption, threat detection, URL filtering, etc.).
Key design decision points
- Intra-subnet / same-VLAN traffic never hits a router → any solution that requires L3 forwarding is instantly disqualified.
- Deep packet inspection → only a real stateful firewall (ASA, Firepower, FortiGate, Checkpoint, Palo Alto) can do L7/NGSI features; switch ACLs are L2–L4 only.
Final architecture logic – Why only transparent firewall works
| Requirement | Transparent Firewall (Bump-in-the-wire) | Routed Firewall | VLAN ACL | ZBF on L3 Device |
|---|---|---|---|---|
| Controls traffic inside same subnet | Yes (L2 transparent, same subnet on both sides) | No (requires new subnet) | Yes | No (requires routing) |
| Deep packet inspection (L7, NGFW) | Yes (full ASA/FTD/Firepower feature set) | Yes | No (L2-L4 only) | Limited (ZBF is L3-L4 + basic Zone-Policy) |
| No IP address on firewall | Yes | No | Yes | No |
| Minimal topology change | Yes | No | Yes | No |
Transparent mode (sometimes called “bridge-mode”) turns a full-featured NGFW into an L2 device:
- Two interfaces in the same bridge-group, same subnet
- Learns MAC addresses, forwards like a switch
- Still performs full stateful DPI, App-ID, TLS decrypt, threat prevention, etc.
Real-world deployment example (Cisco Firepower/ASA):
interface GigabitEthernet0/0 nameif outside bridge-group 1 security-level 0
interface GigabitEthernet0/1 nameif inside bridge-group 1 security-level 100
interface BVI1 ip address 10.10.10.254 255.255.255.0 ! only for management
Traps & Common Mistakes
- A & D → both require routing → break same-subnet requirement.
- B → VLAN ACLs/PACLs are fast and cheap but only L2-L4; zero deep packet inspection capability.
- Many candidates pick ZBF because they remember “zone-based”, but ZBF still needs L3 boundaries.
CCDE-level takeaway
When the business says:
“We need stateful L7 inspection inside a single VLAN/subnet without changing IP addressing” → there is only one technology in the entire Cisco (and industry) portfolio that satisfies it: Transparent-mode NGFW.
It is the de-facto standard for data center micro-segmentation when L2 adjacency must be preserved (VMware clusters, Oracle RAC, Hadoop, etc.).
Question 15
An architect prepares a network design for a startup company. The design must be able to meet business requirements while the business grows and divests due to rapidly changing markets. What is the highest priority in this design?
A. The network should be hierarchical
B. The network should be modular.
C. The network should be scalable.
D. The network should have a dedicated core.
Correct Answer: B
📌Answers & Analysis
Correct Answer: B
(The network should be modular.)
Scenario overview
This is a startup in a fast-moving, unpredictable market (typical FinTech, BioTech, SaaS, or Web3 company).
Business reality:
- One day they raise a $200 M round and triple headcount → explosive growth
- The next day they pivot, sell an entire business unit, or get acquired → sudden divestiture
- New applications, cloud migrations, zero-trust projects, and M&A happen every quarter
In this environment, the network will be constantly reconfigured, extended, and partially torn down.
Key design decision points
- Modularity is the only attribute that directly enables painless growth AND painless divestiture.
- Add a new module (new office, new security zone, new cloud interconnect) → zero impact on existing modules.
- Sell or shut down a business unit → simply remove or isolate its module without touching the rest of the network.
- Scalability (C) is important, but it only solves growth — it does not help when you have to shrink or surgically remove parts.
- Hierarchy (A) and dedicated core (D) are good practices, but they are subordinate to modularity. In fact, the classic Cisco three-tier design is valuable because it is modular (access, distribution, core modules).
Final architecture logic – Why B is the highest priority
Direct quote from the official Cisco Press CCDE book (Chapter 1 – Network Design):
“Whereas with the modular design approach, if any given module faces an issue such as a security breach or the addition or removal of modules, there should be no need to redesign the network or introduce any effect to the other modules… modularity can promote design simplicity, flexibility, fault isolation, and scalability.”
The famous Figure 1-7 in that chapter literally places Modularity in the center, with arrows pointing outward to flexibility, scalability, fault isolation, and manageability.
In startup language:
Modular = “We can plug in or rip out entire network chunks without causing a company-wide outage or redesign project.”
Traps & Common Mistakes
- Many candidates reflexively pick C (scalable) because startups grow fast → but the question explicitly says “grows and divests” → only modularity solves both directions.
- Hierarchical and dedicated core are classic campus answers, but they are secondary when the primary driver is rapid change and divestiture.
CCDE-level takeaway
For any environment with high rates of change, M&A, spin-offs, or frequent restructuring, the #1 design principle is always modularity.
Everything else (scalability, resiliency, hierarchy) is built on top of a clean modular foundation.
The free sharing feature is now closed. You can visit Leads4Pass 400-007 to get the complete 410 exam practice questions and answers.
How to Analyze CCDE Exam Questions Like an Expert
Instead of jumping to a conclusion, break each question into layers: business requirement, technical condition, design constraint, and operational impact. This layered thinking helps you justify every design choice.
True mastery is when you understand not only what works, but why alternatives don’t.
Common Challenges Faced by CCDE Candidates
Many candidates fail not due to lack of knowledge but due to misinterpretation of scenario context. Time pressure further complicates decision-making, making structured thinking more important than speed.
Recommended Resources for CCDE 400-007
A practical starting point for many candidates is
CCDE 400-007 Exam Practice Resource (Leads4Pass 410 Q&A)
This platform offers scenario-based materials that complement official documentation and self-study labs. When used correctly, it becomes a strong supporting tool in your preparation strategy.
Final
The CCDE 400-007 exam isn’t designed to intimidate; it’s designed to transform your thinking. By integrating structured analysis, updated questions, and real experience, you’re not just preparing for an exam — you’re shaping your identity as a network architect. Stay patient, stay analytical, and keep evolving.
FAQs
1. Is the CCDE exam purely technical?
No. It heavily emphasizes business requirements, constraints, and long-term design strategy.
2. Are the free CCDE 400-007 questions similar to the real exam?
High-quality curated questions can closely match the logic and scenario complexity of the actual exam.
3. How long should I prepare for CCDE?
Most candidates require 3–6 months depending on experience level.
4. Is CCDE worth pursuing in 2025/2026?
Absolutely. It is one of the most respected and highest-paying network architecture certifications.
5. Do I need CCIE before CCDE?
No. CCIE is not required—but strong real-world design experience is essential.
Comments are closed.